
由於AutoEncoder在訓練時,每筆數據皆為單一狀況,可以視為數據為Independent,在數字1及數字7中間的變化難以預計。但VAE則不相同,由於Encode向量中有加入Noise,所以數字1及數字7中間Encode向量需要同時還原回1及7,Loss計算時會使Model取一個中間值,使計算數字1及數字7時的Loss最小。因為以上原因,所以會使資料呈現連續狀態,中間擁有逐漸變化的過程。
真實狀況
其方法希望利用VAE找出與原始資料相關的機率分布,使其為一個連續函數,如同GMM(Gaussian Mixture Model)。

將原始數據(紅色線)使用3個Gaussian綜合表示,假設輸入的數據為 x,其數據真實分布為 P(x),而這個分布是未知的,因此使用與GMM相似的表示法,轉化為:


也就是從原始數據中擬合的一個高斯分佈P(m)其中的一點P(x|m),而P(x)就是所有高斯採樣的總合。而GMM為有限的Gaussian組合,為離散有限組合(Discrete),而VAE可以創造出更加連續的組合,根據輸入資料可產生不同排列組合的GMM,近似連續狀態(Continuous)。
VAE架構:

VAE與原始AutoEncoder的架構雷同,皆是Encoder及Decoder的架構,但差異為Encode後的結果不同,VAE將輸出分為m(mean)及σ(variance),產生mean及variance就是為了模擬GMM,使其為Gaussian所組成的向量,之後將Code再經過Decoder還原回原始資料。其中σ會經過exp()後再乘上Normal Distribution,目的為使variance必為正數。
相比原始AutoEncoder,多了variance後,還需要對其多加限制,假設不對其做限制,variance就可能為0,使Encode向量無Noise,變化較小,因此與原始AutoEncoder無差異。這時就需要對其多加入限制,Loss Function如下:

前面兩項為variance之限制條件,使σ越接近0越好,其曲線如下圖:

在Minimize Loss Function時,σ之目標會逐漸趨近於0。而σ為0時,會再經過exp(),因此variance會為1,使Encode後的Code保證有一定的Noise加入。
而對應Output的Loss則是計算KL divergence,假設輸入為x,輸出為x’,Loss Function則表示為(ELBO):
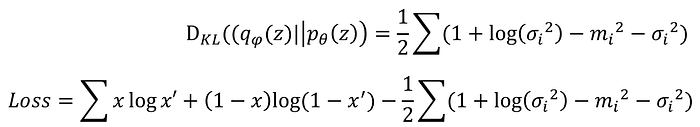
這個公式是利用Evidence Lower Bound(ELBO)推導而來,但詳細過程目前還未了解...
VAE效果
將VAE使用於MNIST上,數據可視化後可以看到各個數字分布會較為集中,可以觀察到數字變化的效果,為連續的狀態

